EC3: Elastic Cloud Computing Cluster
Elastic Cloud Computing Cluster
Elastic
Cloud Computing Cluster (EC3) is a tool to create elastic virtual
clusters on top of Infrastructure as a Service (IaaS) providers, either
public (such as Amazon Web Services, Google Cloud or Microsoft Azure), on-premises (such as OpenNebula and OpenStack) or federated, such as EGI FedCloud or Fogbow. We offer recipes to deploy Kubernetes, TORQUE, SLURM, SGE, HTCondor, Mesos, and Nomad clusters that are self-managed by the service.
EC3 proposes the combination of Green computing, Cloud computing and HPC techniques to create a tool that deploys elastic virtual clusters on top of IaaS Clouds. EC3 creates elastic cluster-like infrastructures that automatically scale out to a larger number of nodes on demand up to a maximum size specified by the user. Whenever idle resources are detected, the cluster dynamically and automatically scales in, according to some predefined policies, in order to cut down the costs in the case of using a public Cloud provider. This creates the illusion of a real cluster without requiring an investment beyond the actual usage. Therefore, this approach aims at delivering cost-effective elastic Cluster as a Service on top of an IaaS Cloud.
As a summary, the main objectives of EC3 are:
To facilitate the access to computing platforms for non-experienced users.
To maintain the traditional work environment, with clusters configured with a well-known middleware.
To offer the automatic management of elasticity, reducing costs (public cloud) and energy expenditure (private cloud).
To support the automatic configuration of the application execution environment.
To be compatible with a wide range of cloud providers (public, federated and on-premises).
To support hybrid clusters.
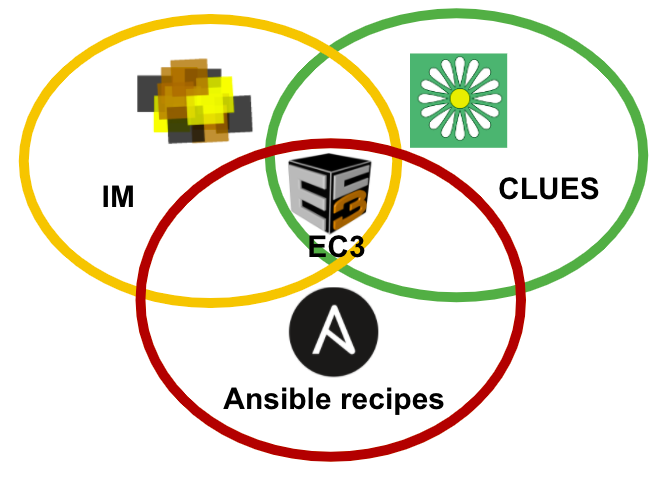
Figure 1.- Components of EC3
EC3 relies on different tools to achieve its goals. These tools are:
The Infrastructure Manager (IM) is a tool that eases the access and the usability of IaaS clouds by automating the VMI (Virtual Machine Image) selection, deployment, configuration, software installation, monitoring and update of Virtual Appliances. It supports APIs from a large number of virtual platforms, making user applications cloud-agnostic. In addition it integrates a contextualization system to enable the installation and configuration of all the user required applications providing the user with a fully functional infrastructure.
CLUES is an energy management system for High Performance Computing (HPC) Clusters and Cloud infrastructures. The main function of the system is to power off internal cluster nodes when they are not being used, and conversely to power them on when they are needed. CLUES system integrates with the cluster management middleware, such as a batch-queuing system or a cloud infrastructure management system, by means of different connectors.
Ansible is an IT automation engine that automates cloud provisioning, configuration management, application deployment, intra-service orchestration, and many other IT needs. Designed for multi-tier deployments, Ansible models your IT infrastructure by describing how all of your systems inter-relate, rather than just managing one system at a time. It uses no agents and no additional custom security infrastructure, so it's easy to deploy - and most importantly, it uses a very simple language (YAML, in the form of Ansible Playbooks) that allow you to describe your automation jobs in a way that approaches plain English.
Thus, EC3 relies on IM to deploy the machines and on CLUES to automatically manage the elasticity. Moreover, the tool offers a set of predefined templates to configure the resources through Ansible: from well-known local resource management systems, such as Kubernetes, Mesos, SLURM, Torque, HTCondor or Nomad; scientific tools like the Galaxy framework, or software packages an utilities such as Octave or GNUplot. The complete list of the available templates distributed by default with the EC3 tool can be seen in the official Github repository.
1.- Architecture
Figure 2 summarizes the main architecture of EC3. The deployment of the virtual elastic cluster consists of three main phases. The first one involves starting a Virtual Machine (VM) in the Cloud to act as the cluster front-end; the second one will take care of the configuration of this VM; while the third one involves the automatic management of the cluster size, depending on the workload and the specified policies.
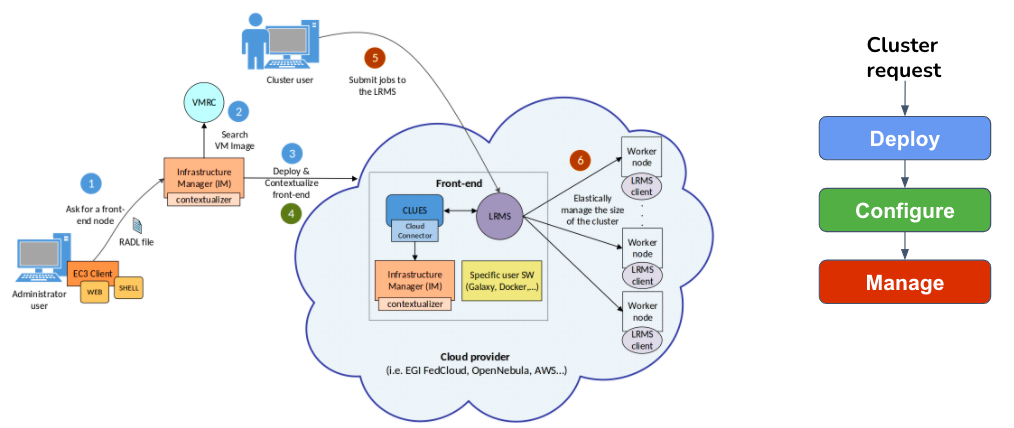
Figure 2.- Architecture of EC3
For the first phase (deployment), the user can use the EC3 Command Line Interface (CLI) or the EC3 web portal to start the creation of the cluster, providing it with the following information:
Specification of the cluster machines: front-end and working nodes characteristics, regarding both hardware and software (OS, LRMS, additional libraries, etc.). These requirements are taken by the EC3 client to create a request to the IM, asking for the required resources in the cloud provider specified by the user. Also the user has to specify the tools and libraries he/she wants to install in the machines. For that, the user can employ the default RADLs provided by the tool (such as the instructions required to configure a SLURM cluster or the hybrid features), but he/she can also include additional customized RADLs to configure the cluster for specific applications. Inside the RADLs, the characteristics of the nodes are given in terms of hardware, software, and configuration requirements.
Maximum cluster size: This serves to establish a cost limit in case of a workload peak. The maximum cluster size can be modified at any time once the virtual cluster is operating. Thus, the sysadmins can adapt the maximum cluster size to the dynamic requirements of their users. In this case the LRMS must be reconfigured to add the new set of virtual nodes and in some cases it may imply a LRMS service restart.
Authentication for the cloud provider chosen: the authorization file stores in plain text the credentials to access the cloud providers and the IM service. Each line of the file is composed by pairs of key and value separated by semicolon, and refers to a single credential. More details can be found here.
According to the data specified by the user, EC3 contacts the IM to deploy the front-end. First, the IM selects the appropriate VMI for the front-end. A particular user-specified VMI can be selected, or rely on IM to choose the most appropriate available VMI (step 2) by considering the requirements in the RADL file. The IM then chooses the IaaS cloud provider and the type of instance according to the requirements specified by the user (step 3).
Phase 2 (configuration) starts when the aforementioned instance is available by installing and configuring all of the required software that is not already preinstalled in the VM (step 4). In this phase, all of the required software is installed to configure the instance as the front-end of the cluster, which involves deploying: (i) a new IM in the front-end for deploying the worker nodes; (ii) Ansible to configure the new nodes; (iii) CLUES to manage the elasticity of the cluster; (iv) the LRMS selected by the user; and (v) (optionally) additional software packages specified by the user. If the cluster needs to be configured as a hybrid, VPN or SSH tunnels must be configured to interconnect all of the nodes (selected by the user). Moreover, BLCR and NFS are configured if the user enables the use of spot instances.
Finally, phase 3 (management)
starts after the front-end has been deployed and configured. At this
point, the virtual cluster (composed only by the front-end node) becomes
totally
autonomous and users can submit jobs to the LRMS either from the cluster
frontend or from an external node with job submission capabilities
(step 5). The user
will have the illusion of a cluster where the number of nodes is
specified as the
maximum size. CLUES monitors the working nodes and intercepts the job
submissions as they arrive at the LRMS, thereby allowing the system to
dynamically
manage the cluster size transparently to the LRMS and the user by
scaling up and
down on demand. Similar to the deployment of the frontend, CLUES
internally
employs the IM configured in the front-end during phase 2 to deploy
additional
VMs for use as working nodes in the cluster (step 6). When these nodes
are available, they are integrated automatically into the cluster as new
available nodes for
the LRMS.
2.- Deployment models
EC3 supports a wide variety of deployment models (i.e. cluster behaviour). In this section, we provide information about all of them and an example of configuration for each deployment model. Specifically, EC3 supports three deployment models:
Basic structure (homogeneous cluster): An homogeneous cluster is composed by working nodes that have the same characteristics (hardware and software). This is the basic deployment model of EC3, where we only have one type of
systemfor the working nodes.Heterogeneous cluster: this model allows that the working nodes comprising the cluster can be of different characteristics (hardware and software). This is of special interest when you need nodes with different configuration or hardware specifications but all working together in the same cluster. It also allows you to configure several queues and specify from which queue the working node belongs to.
Cloud Bursting (Hybrid clusters): the third model supported by EC3 is Cloud Bursting. It consists on launching nodes in two or more different Cloud providers. This is done to manage user quotas or saturated resources. When a limit is reached and no more nodes can be deployed inside the first Cloud Provider, EC3 will launch new nodes in the second defined Cloud provider. This is also called a hybrid cluster. The nodes deployed in different Cloud providers can be different also, so heterogeneous clusters with cloud bursting capabilities can be deployed and automatically managed with EC3. The nodes would be automatically interconnected by using VPN or SSH tunneling techniques.
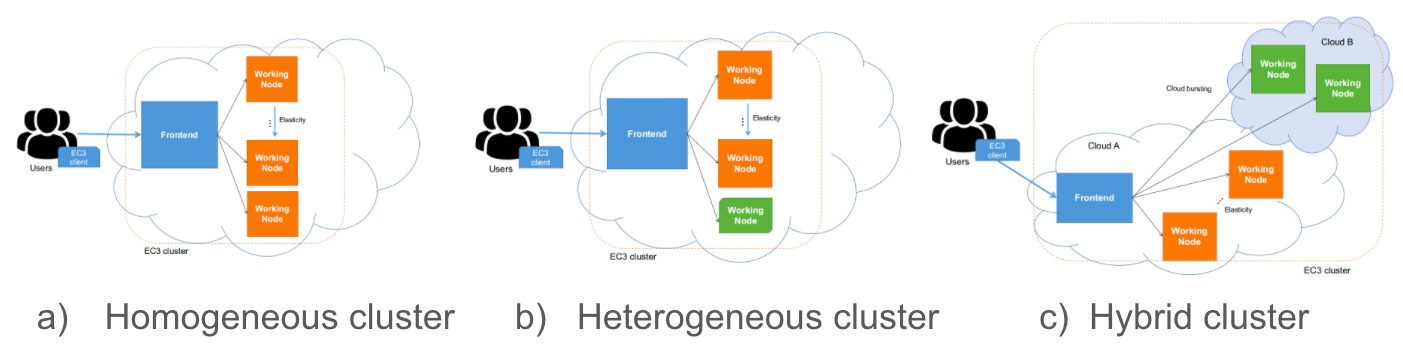
Fig 3. EC3 Deployment Models.
3.- Elasticity management
Elasticity Management is the ability to adapt the size of the cluster to the workload dynamically and automatically. There are mainly two types of elasticity, horizontal, and vertical.
Horizontal Elasticity: increase / decrease the number of VMs. This is the type of elasticity that EC3 supports.
Vertical Elasticity: increase/decrease the characteristics of the VM (in terms of CPUs and RAM memory).
EC3 implements horizontal elasticity by terms of CLUES. This tool facilitates the self-management of the cluster, i.e, the elasticity rules are evaluated from the main node of the cluster without requiring any external entity in charge of monitoring the cluster to decide when to increase / reduce the size of the cluster.
Moreover, the elasticity should not affect the execution of tasks, ensuring transparency. Thus, the dynamic variation of the size of the cluster is unnoticed both for tasks and users.
As it is said previously, the elasticity module is responsible for dynamically adding and removing nodes from the cluster by monitoring the LRMS. Regarding the deployment policies, CLUES supports a wide range of possible configurations, that can be made directly in its configuration file. As an example, we can highlight the next ones:
- Deployment policies (scale out):
- On demand: a node is deployed for each job that comes to the queue.
- Bursts: deploys a group of VMs for each job in the queue, assuming that if a job arrives at the LRMS, there is an increased chance that new jobs will arrive soon. (i.e HTC applications).
- Undeployment policies (scale in):
- On demand: ends idle nodes when there are no pending jobs in the LRMS queue.
- Delayed power off: inactive nodes turn off after a certain configurable period of time. (i.e public clouds)
CLUES supports the monitoring and management of several LRMS, such as SLURM, Kubernetes and Mesos, among others. As it is implemented based on a plug-in structure, a new plug-in can be easily developed to support a new batch system. All the current available plug-ins can be seen here.
You have achieved now a good understanding of EC3 and how its clusters work. Please, go to the brief questionnaire below to check your knowledge: