A story of integration: SAPS
A story of integration: SAPS
SAPS (SEB Automated Processing Service) is one of the ten Thematic Service of the EOSC Synergy project. SAPS is a service to estimate Evapotranspiration (ET) and other environmental data that can be applied, for example, on water management and the analysis of the evolution of forest masses and crops. SAPS allows the integration of Energy Balance algorithms (e.g. Surface Energy Balance Algorithm for Land (SEBAL) and Simplified Surface Energy Balance (SSEB)) to compute the estimations that are of special interest for researchers in Agriculture Engineering and Environment. These algorithms can be used to increase the knowledge on the impact of human and environmental actions on vegetation, leading to better forest management and analysis of risks.
In this section of the course,
we will go through the example of integration of the SAPS Thematic
service with Kubernetes and EC3. The service
is currently used by SAPS to deploy and configure a Kubernetes cluster
automatically with SAPS running on it. Also, EC3 is used to manage the
elasticity of the K8s cluster automatically. The tool facilitates the
deployment and management of SAPS service.
Figure 1.- Logos of the three main technologies involved: EC3, Kubernetes and SAPS.
1.- SAPS architecture
Figure 2 shows the architecture of SAPS. This architecture is automatically deployed, configured and managed by EC3. All the SAPS components run on a K8s cluster, so the location of each component depends on the K8s scheduler. The only component that needs to run in the front machine of the cluster is the Dashboard, so it can be exposed using the public IP of the front to the users.

Figure 2 - Architecture of SAPS deployed on a K8s cluster by EC3.
As shown in figure 2,
the user interacts with the system through the Dashboard, a web-based
GUI that serves as a front-end to the Submission Dispatcher component.
Through the Dashboard, the user, after successfully logging in, can
specify the region, the period that he/she wants to process, as well as
the particular Energy Balance algorithm that should be used. The
execution consists of a three-stage workflow: input download, input
preprocessing, and algorithm execution. With this data, the Dashboard creates
the processing requests and submits them sequentially to the Submission
Dispatcher. Each request generated corresponds to the processing of a
single scene. The Submission Dispatcher creates a task associated with
the request in the Service Catalog database (PostgreSQL). This element
works as a communication channel between all SAPS components. Tasks have
a state associated with them that is used to indicate which component
should act next in the processing of the task. The
Scheduler component is in charge of orchestrating the created tasks
through various states until they finish. It uses Arrebol to create and
launch the tasks on the K8s cluster as Kubernetes Jobs. A Job downloads
the appropriate Docker image from Docker Hub and starts its execution.
Input and output files are stored on a Temporary Storage NFS that is
accessible to all Jobs running at the cluster. Arrebol monitors all
active Jobs to find out the status of the executions, and updates the
state of each task in the Service Catalog, accordingly. The Archiver
component collects the data and metadata generated by tasks whose
processing has either successfully finished or failed. The associated
data and metadata are copied from the NFS Temporary Storage, using an
FTP service, to the Permanent Storage, which uses the Openstack Swift
distributed storage system, where they are made securely and reliably
available to the users. Through
the Dashboard, the user can also have access to the output generated by
completed requests. The interface to access the output data uses a
world map. A heat-map, segmented based on the standard tiles used by the
Landsat family of satellites, is superimposed to the world map. The
heat-map gives an idea of the number of scenes for each Landsat tile
that have already been processed.
2.- SAPS web interface & demo
The SAPS dashboard is designed to facilitate the deployment and management of Landsat analysis tasks. Figure 3 shows the appearance of it for (a) submission of a new processing request and (b) access to the output data.
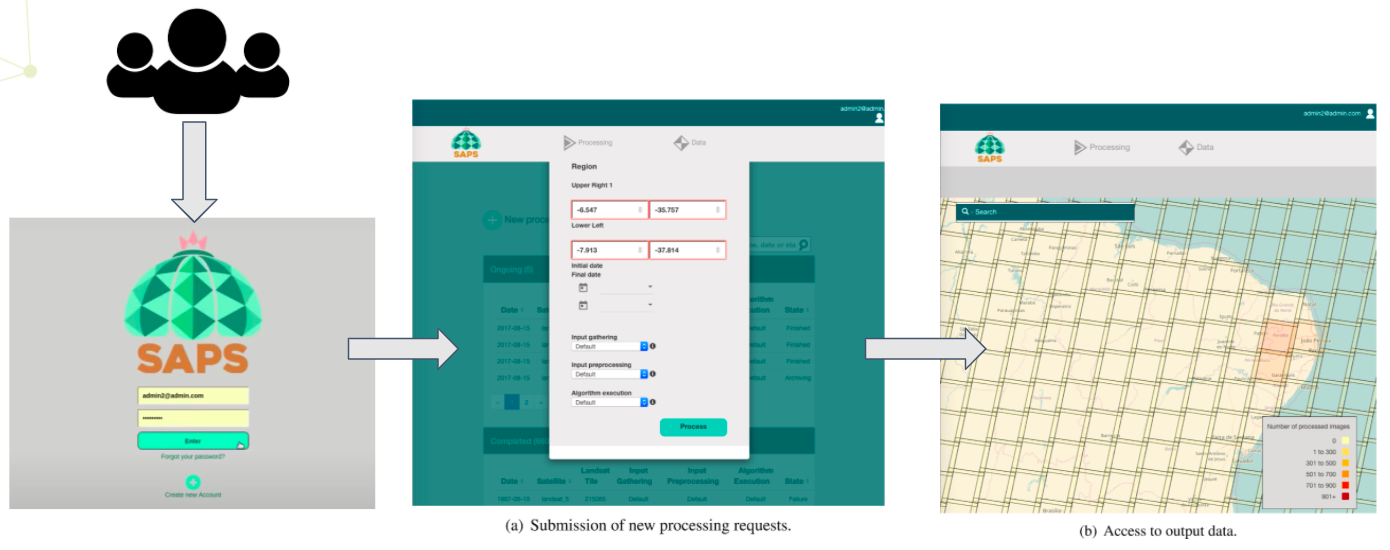
Figure 3 - Snapshot of the SAPS interface.
We have prepared a demonstration video where you can see EC3 in action, deploying SAPS on top of an OpenStack cloud, and how the users access the cluster to deploy several tasks that cause the elasticity manager to take action and deploy the requested nodes to execute the workload. Please, watch the next video to find all the details:
The
demo is mainly divided in three parts. The first part of the video
shows the deployment of the
SAPS application on top of an elastic Kubernetes cluster by terms of
EC3. The video shows the command needed to deploy the cluster by using
EC3 CLI and how to connect to it. Once inside the cluster, in the video
we show how the SAPS microservices are
deployed in Kubernetes and wait for an initial working node to run. This
action is automatically done by CLUES, the elasticity manager of the
cluster. On the second part of the video, we access SAPS Dashboard and
show a bit the graphical interface it
offers to create and monitor the status of the tasks. We also explain
the required parameters SAPS asks the user to create a new landsat
workflow analysis. Finally, the third part of the video shows an example
execution created in the SAPS dashboard,
and how the elastic Kubernetes cluster adapts automatically its size to
cope with the 62 tasks that compose the workflow. The last part of the
video shows the graphical interface that SAPS offers to access the
output of the previously executed workflows,
that is based on a world heat map
3.- Deploy your own SAPS instance
You can use EC3 CLI to deploy your own SAPS instance. Let's see how to do it!
Pre-requisites:
To already have installed EC3 CLI (you can use the docker image, or install it).
An account in EGI FedCloud to access computing resources.
A site with support to Openstack Swift. This is the storage solution used by SAPS archiver, so you must deploy SAPS in a EGI site that offers this kind of storage.
(Optional) To be part of the SAPS VO (saps-vo.i3m.upv.es). You can enroll the VO by clicking here.
Preparing the deployment:
First, you will need to create the proper authentication file to access IM service and also the EGI FedCloud provider. For that, create a file called 'auth_egi.dat'with the following information:
id = egi; type = OpenStack; host = https://ostserver:5000; username = egi.eu; auth_version = 3.x_oidc_access_token; password = <access_token>; tenant = openid; domain = EGI_access
id = im; type = InfrastructureManager; username = <your_user>; password = <your_pass>
The 'password' value in the first line is your EGI 'access token' that you can obtain from this web portal: https://aai.egi.eu/fedcloud/. Moreover, the 'host' label has to point to the site provider you have chosen to deploy the cluster (remember that support for Openstack Swift is required). You can obtain the full list of available sites from the EGI AppDB. Regarding the user and password required to access IM service, you can create your own ones adding the values you want. You don't need to have any account previously. IM Server does not store the credentials used in the creation of infrastructures. Then the user has to provide them in every call to EC3 with the option -a/--auth_file.
Now we are going to prepare the recipes we need. We will have to work a bit on the creation of the 'system' recipe, to indicate the characteristics of the virtual machines we need. We recommend you to launch SAPS in a cluster with, at least, the next values:
In the master/front-end node:
2 VCPUs
4Gb of RAM
80 Gb of disk
In the working nodes:
8 VCPUs
16 Gb of RAM memory
100 Gb of disk
For that, we are going to create another file, called 'ubuntu18-openstack' to indicate such requisites and also the operating system. We recommend you to use a fresh Ubuntu 18.04 or 20.04 to deploy SAPS. In our example we have chosen an Ubuntu 18.04 image from the UPV site, that is called 'horsemen.i3m.upv.es'. Also, in this file we have to determine the instance type to use, i.e. the amount of CPU and RAM memory we need for each kind of node (instance_type). You can check the EGI AppDB to find the proper values for your desired site and OS. Finally, we need to add the maximum size of the cluster (ec3_max_instances), i.e. the upper limit to the elasticity in our infrastructure.The file should look like the next ecample:
description ubuntu18-openstack (
kind = 'images' and
short = 'Ubuntu 18.04 amn64 (OpenStack).' and
content = 'Ubuntu 18.04 amd64 (OpenStack).'
)
system front (
instance_type = 'Medium' and
disk.0.os.name = 'linux' and
disk.0.image.url = 'ost://horsemen.i3m.upv.es/609f8280-fbb6-46bd-84e2-5315b22414f1' # Ubuntu 18.04 LTS
)
system wn (
instance_type = 'XLarge' and
ec3_max_instances = 10 and # maximum number of working nodes in the cluster
disk.0.os.name = 'linux' and
disk.0.image.url = 'ost://horsemen.i3m.upv.es/609f8280-fbb6-46bd-84e2-5315b22414f1' # Ubuntu 18.04 LTS
)
Then, we need the recipes that describe how to deploy and configure each SAPS component. Don't worry because we provide
you the specific recipes needed for that. You just need to configure some variables of them. In this repo (https://github.com/ufcg-lsd/saps-docker) you will find the RADL recipes to deploy SAPS, under
the 'ec3_recipe'
folder. The repo also contains the Kubernetes deployment files for each
component, together with the proper configuration. Download the
recipes, add them to the
'templates' folder of EC3 and edit the 'saps.radl' file to configure the variables that are at the end of the file (from line 208 to 218).
Deploy the SAPS cluster:
Finally, you can deploy your SAPS cluster. We are going to use the default instance of IM that is deployed and publicly available at UPV. If you deployed your own instance of IM, please, point to it with the option -u/--restapi-url. In general, use the next command to deploy the cluster:
$ ./ec3 launch KUBESAPS kubernetes nfs-saps saps ubuntu18-openstack -a auth_egi.dat
After some minutes, you will receive the message 'Frontend created successfully!', and the public IP of the front-end machine. You can connect via SSH to the machine or use EC3 CLI to do that:
$ ./ec3 ssh KUBESAPS
That's it! you can start enjoying your SAPS elastic cluster based on Kubernetes! Connect to the frontend to see that the SAPS services are running (for example with the command 'sudo kubectl get services'), if they are still not running, wait a bit because a new node is being added to the cluster triggered by CLUES (you can check it by using the 'clues status' command) to run the SAPS services. Once all the services are up and running, you can access the SAPS Dashboard with your preferred browser and start deploying your tasks!