Benchmarking workflow
Workflows structure
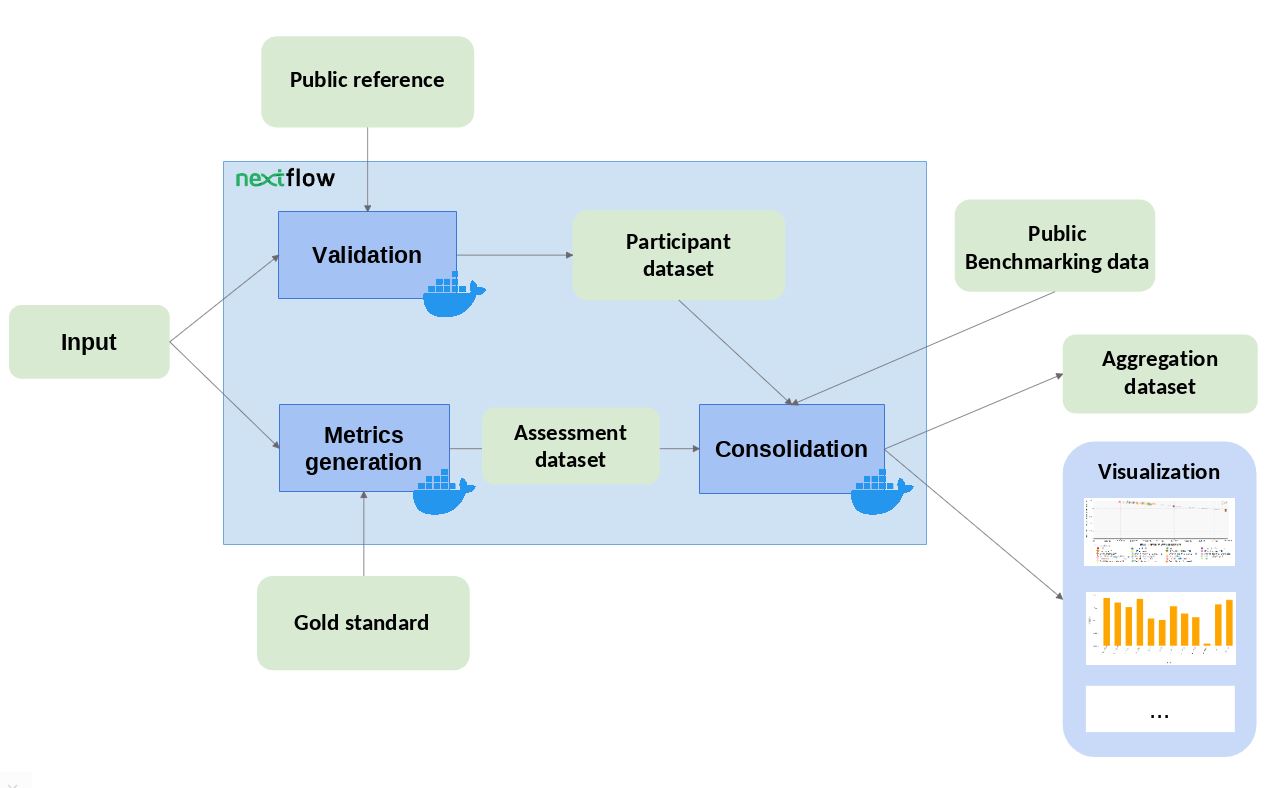
As seen in the Figure below, our benchmarking workflows are composed of three conceptual blocks (that might be formed of one or more workflow steps), which we encourage the communities to follow for compatibility with our system. Those blocks are:
Validation and preprocessing: the input file format is checked and, if required, the content of the file is validated (e.g check whether the submitted file contains certain fields, or compare to a ‘public reference’ dataset to check if the submitted IDs exist). These are the parameters involved in this step (for more information about parameters visit the ‘workflow parameters’ structure):
Inputs: input, community_id, challenges_ids, participant_id, public_ref_dir
Outputs: validation_result (and an exit status which indicates whether the validation was successful or not).
Metrics Generation: the predictions are compared with the ‘Gold Standards’ provided by the community, which results in one or more performance metrics (e.g. Precision & Recall). These are the parameters involved in this step (for more information about parameters visit the ‘workflow parameters’ structure):
Inputs: input (depending on whether the validation step was successful), community_id, challenges_ids, participant_id, goldstandard_dir.
Outputs: assessment_results.
Consolidation: the benchmark itself is performed by merging the tool metrics with the rest of the community’ reference data. The results are provided in JSON format and SVG format (scatter plot). These are the parameters involved in this step (for more information about parameters visit the ‘workflow parameters’ structure):
Inputs: assessment_results, validation_result, assess_dir
Outputs: outdir, data_model_export_dir
For reproducibility and interoperability purposes, OpenEBench encourages communities managers to submit their pipelines wrapped with a workflow management system (e.g Nextflow) and its tools containerized (e.g. Docker).
NOTE for developers: In order to make the workflow containers reproducible and stable in the long-term, make sure to use specific versions in the container base image (e.g.ubuntu:16.04, NOT ubuntu:latest).
For more information about how to build your own benchmarking workflow, see our TCGA sample workflow at https://github.com/inab/TCGA_benchmarking_workflow.
NOTE for developers: In order to make your workflow compatible with the OpenEBench infrastructure, please make sure to use the same 3-step structure, output formats, and parameter names in it.
Workflow parameters
Description of the parameters used in OEB benchmarking workflows:
INPUTS
input: predictions file submitted by the participants
public_ref_dir: directory which contains one or more reference files used to validate input data.
participant_id: name of the tool used for the predictions.
goldstandard_dir: directory where the ‘gold standard’ or ‘reference data’ to compute the metrics are found.
challenges_ids: list of challenges (performance evaluation methods) which are performed in the benchmark - if you have only one evaluation method, just define a name for it.
assess_dir: directory where the performance metrics for other participants to be compared with the submitted one are found. If there is no other benchmark data yet, an empty aggregation dataset should be defined.
community_id: name or OEB permanent ID for the benchmarking community.
OUTPUTS
validation_result: file path where it is written the validated participant JSON, which corresponds to a minimal dataset compatible with the Elixir Benchmarking Data Model.
assessment_results: file path where it is written the set of assessment datasets in JSON, which corresponds to minimal datasets compatible with the Elixir Benchmarking Data Model.
outdir: directory where the run results are saved - one or more aggregation files used by the visualization, and several SVG/PNG plots.
statsdir: directory where all nextflow statistics (timeline, trace, report…) are written.
data_model_export_dir: file where all the datasets generated during the workflow, which are compatible with the Elixir Benchmarking Data Model, are merged into a single JSON, which is ready to be validated and pushed to Level 1.
otherdir: directory where other community’ specific results can be written.
NOTE for developers: In order to make your workflow compatible with the OpenEBench infrastructure, please make sure to use the same parameter names in it.