Step 6
Deploy your service
Now it's time! All the previous steps were just a preparation to create our service. But what is a service? Well a lot of things can actually be a service (always you have users). In our case we are just going to create a small example in a big world of options.
The target of this step is to have our service containers running on the kubernetes cluster we have just deployed with the previous steps. There are currently 2 available tools for deployment already installed in our cluster by the Infrastructure Manager:
- Kubeapps, a graphical interface for deployment of common utilities.
- Kubernetes dashboard, a graphical tool for cluster management.
In terms of service deployment, option 2 is more complete, basically because it provides all management functionalities. However, it requires knowledge on Kubernetes. On the other hand, option 1 is easier but has a limited offer of tools. If you need to deploy a custom service container, you need to do it through option 2, for common microservices such as standard databases or graphical interfaces you can use option 1.
Remember that the Infrastructure Manager provides you a Kubeapps endpoint on the “outputs” generated when deploying your infrastructure.
Figure 1. Kubeapp Catalog
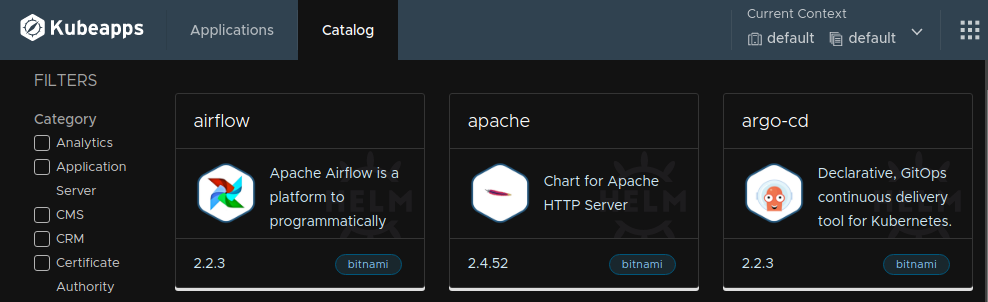
In this step, we are going to use Kubeapps to deploy a graphical dashboard that you can use to visualise data from your thematic service. You will also need a data source, but we will take care of that later. Now navigate to the Kubeapps endpoint and log in using the access token defined when deploying the cluster at step 3 and click on “Catalog” on the navigation panel. Figure 1 shows a list of “charts” that you can use to deploy services at the cluster.
First we are going to deploy a Grafana microservice as a visualisation tool to see graphs of our data. In your kubeapp endpoint catalogue, search and select the tool “Grafana''.
Figure 2. Grafana chart deployment panel

Now, ensure the last version is selected and click on the “DEPLOY” button. A configuration form will appear such as the one at figure 3.
Figure 3. Configuration YAML for Grafana deployment
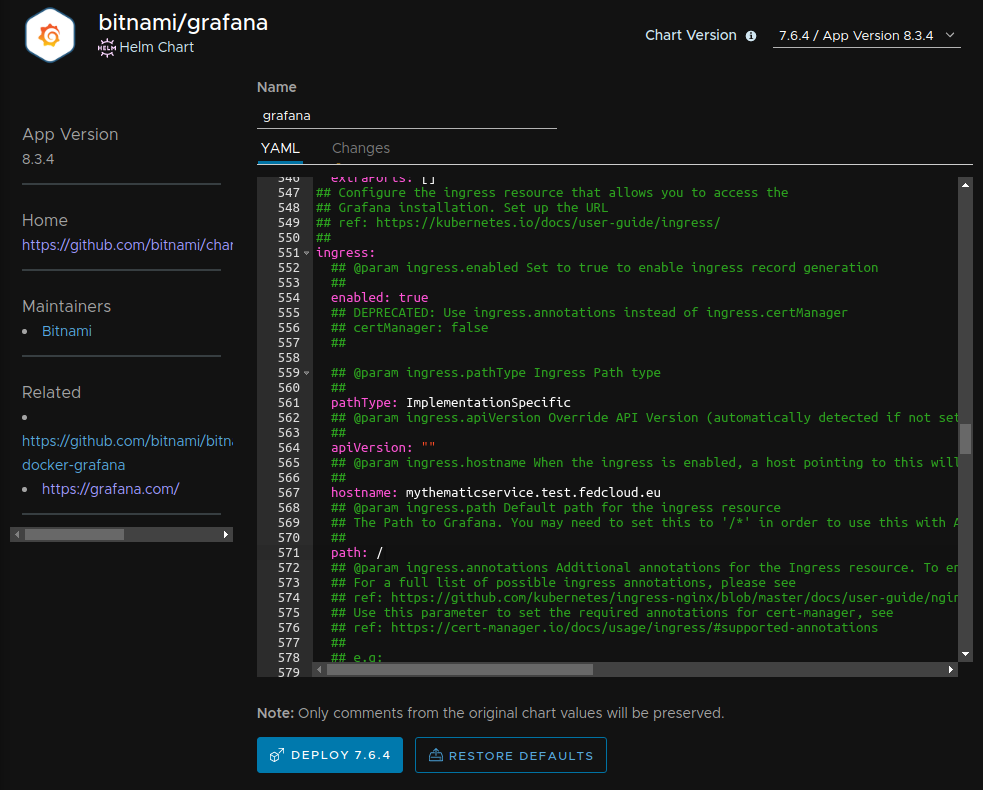
The YAML form shows all the configurable options provided by the application at the repository. Now, before clicking on the “DEPLOY <version>” button, you need to consider which requirements you have for the deployment. In this example we want to deploy the microservice with the following features:
- HTTPS access to the service from the public IP.
- The service is provided at our DNS address.
- The service is provided at root path (Path: /).
HTTPS communications outside the cluster are managed by `ingress` and `cert-manager` which are already configured. However, the example provided uses HTTP inside the cluster which for our case is considered secured. If you share a cluster with other developers you might consider using HTTPS inside the cluster microservice communications as well.
Introduce a name for your deployment (for example “grafana”) and make sure you edit the following fields, leave the rest of options intact unless you understand what you are configuring:
ingress: |
In general, it is not recommended to assign services to the root path of ingress, unless it is a single-purpose k8s.
Now click on the “DEPLOY <version>” button and wait until the Pods are ready. You will see something similar to figure 4 where you can find the admin user name “admin” under the “Installation Notes” and its password at “Application Secrets”.
Figure 4. Application details for grafana service
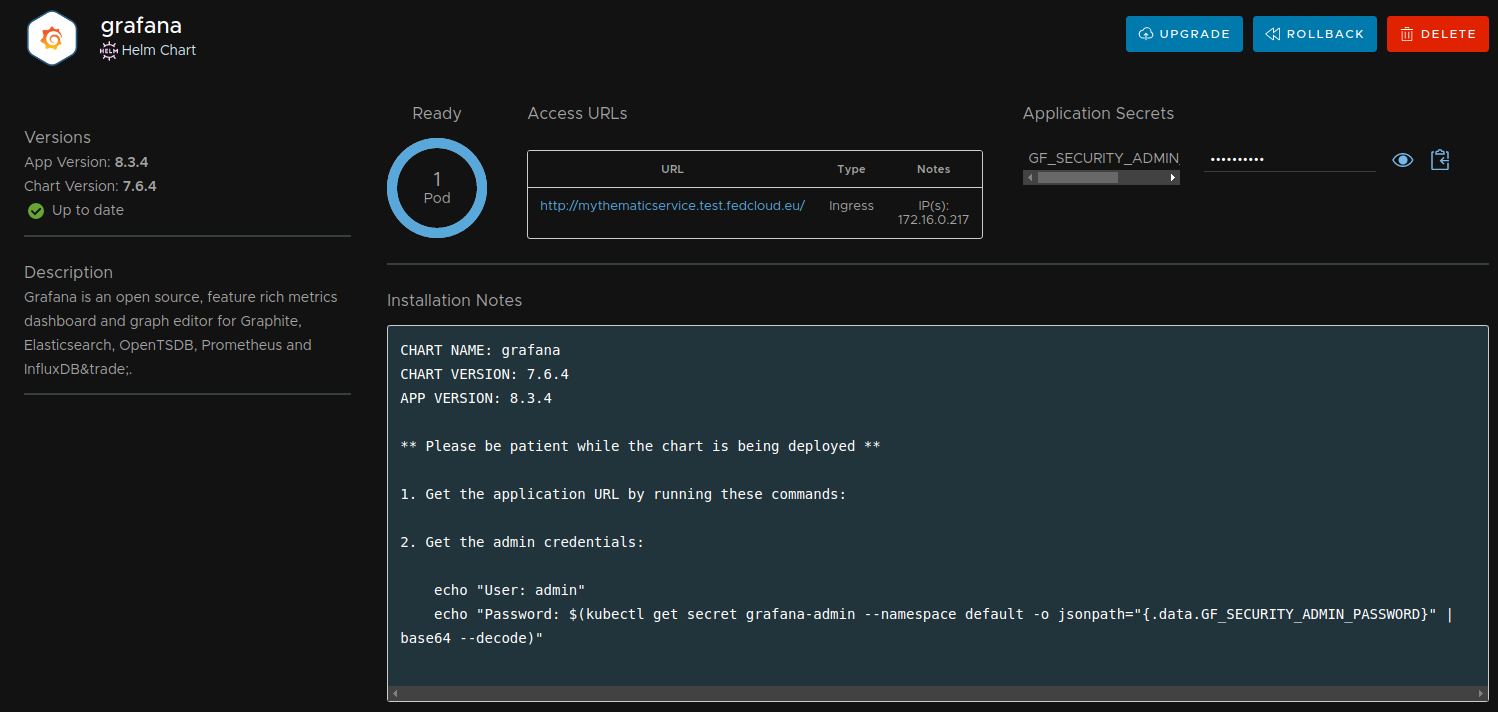
Click on the URL under the “Access URLs” and you will be redirected to the Grafana service login page where you can introduce the admin credentials to start managing your first cluster microservice.
The IP(s) field might indicate the IP configured at the FE which, depending on the OpenStack network configuration, might not match your public service IP.
From this point, feel free to experiment all you like inside your Grafana service. However, sooner or later you will find out that there is not too much to visualise yet (or not real data at least). To fix this, now we are going to deploy a place where to store data. There are multiple options available when using Grafana (see Grafana datasources).
Now that you domain the usage of kubeapp, we are going to repeat the steps, but this time with a postgres service, a database application. We navigate back to the kubeapp catalogue and this time we search for the “chart” postgresql.
We click on the “DEPLOY” button and similarly to Grafana, a configuration form will appear.
Figure 5. Configuration form for postgresql deployment
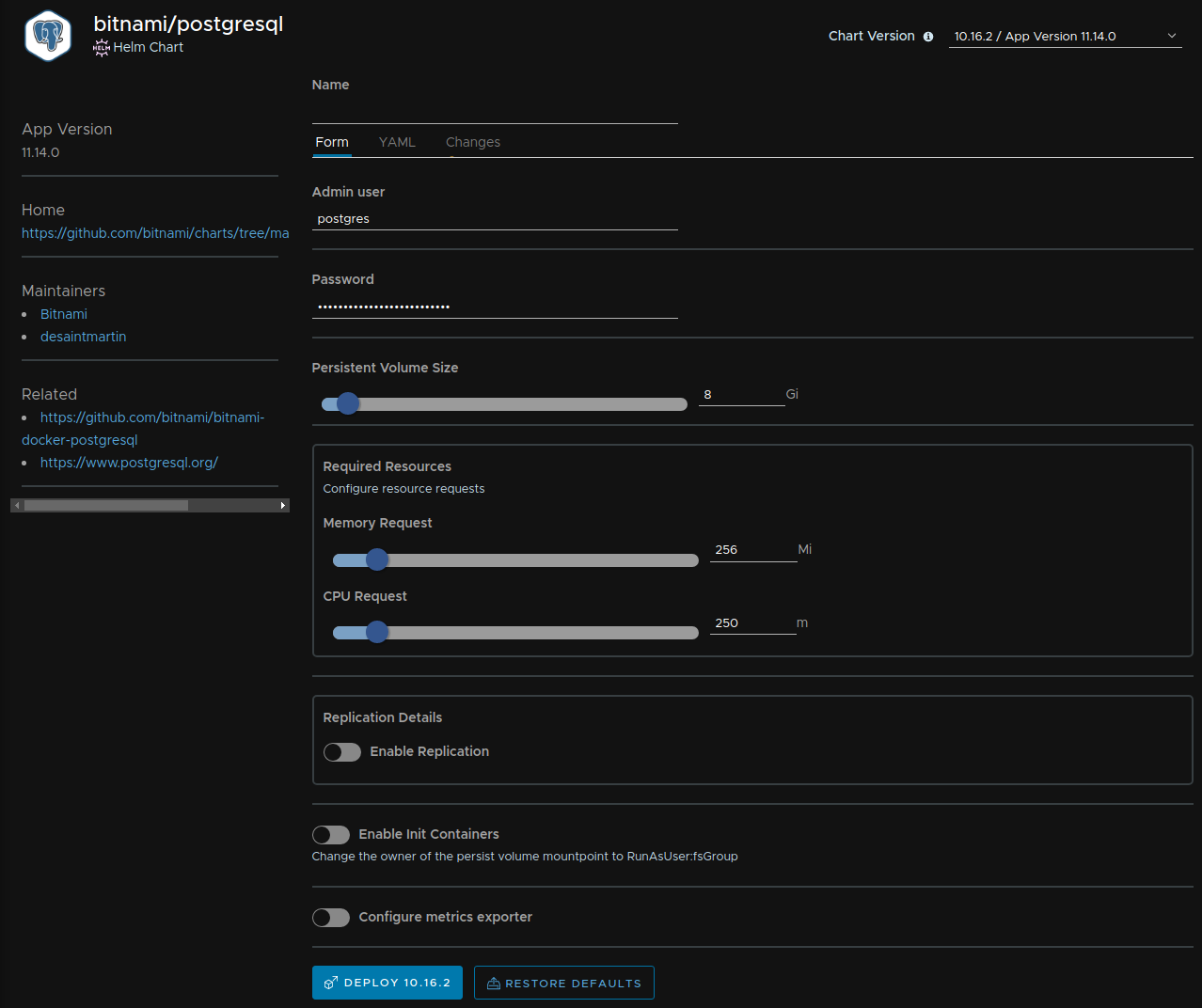
This time the form looks a bit simpler. For our case we do not need too much configuration as we do not need to expose this service to the public (we will connect via ssh proxy). Just make sure to complete the following fields:
- Admin user: Name for the database user administrator.
- Password: Password to log in as admin user.
Once decided and completed, click on the “DEPLOY <version>” button and wait until the pods are ready and the service available.
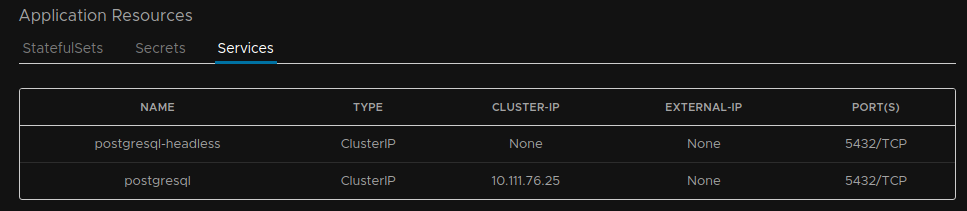
For this case, there will not be an access URL as it is not exposed by ingress. However, you can access the service inside the cluster. You can find the details inside the “Application Resources” at the “Applications” detail panel for postgres, just scroll down from the last page and click on the tab “Services”:
Figure 6. Postgresql deployment services details
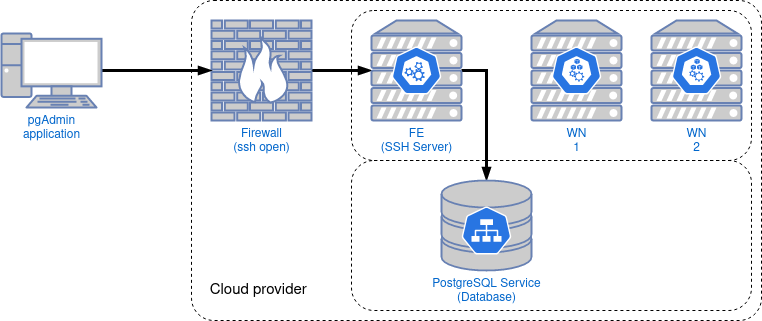
Now lets create the database and tables. However, we cannot access the database from our terminal. To solve this issue, we recommend accessing the database using ssh tunnelling as it is shown in figure 7, although you might directly connect to the FE node and operate from there. Feel free to create the database and follow the next steps the way you feel the best, for example using command line tools. In this tutorial for the commodity of users without deep SQL knowledge, we are going to use pgAdmin.
Figure 7. SSH Tunnelling into a kubernetes Postgresql service
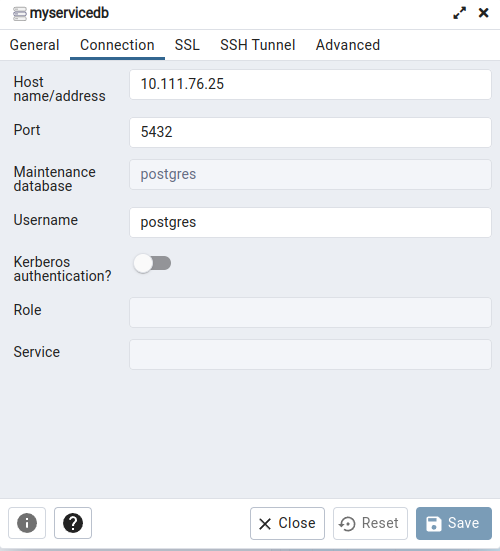
As the first step, we have installed pgAdmin4 in our local machine and enabled a connection using SSH tunnelling. To do so, note the connection details for the database are obtained from the application details at kubeapp (shown in figure 6) whereas the SSH tunnel must use the configuration that you normally use to connect to the FE node.
Figure 8. Database connection details for pgAdmin4

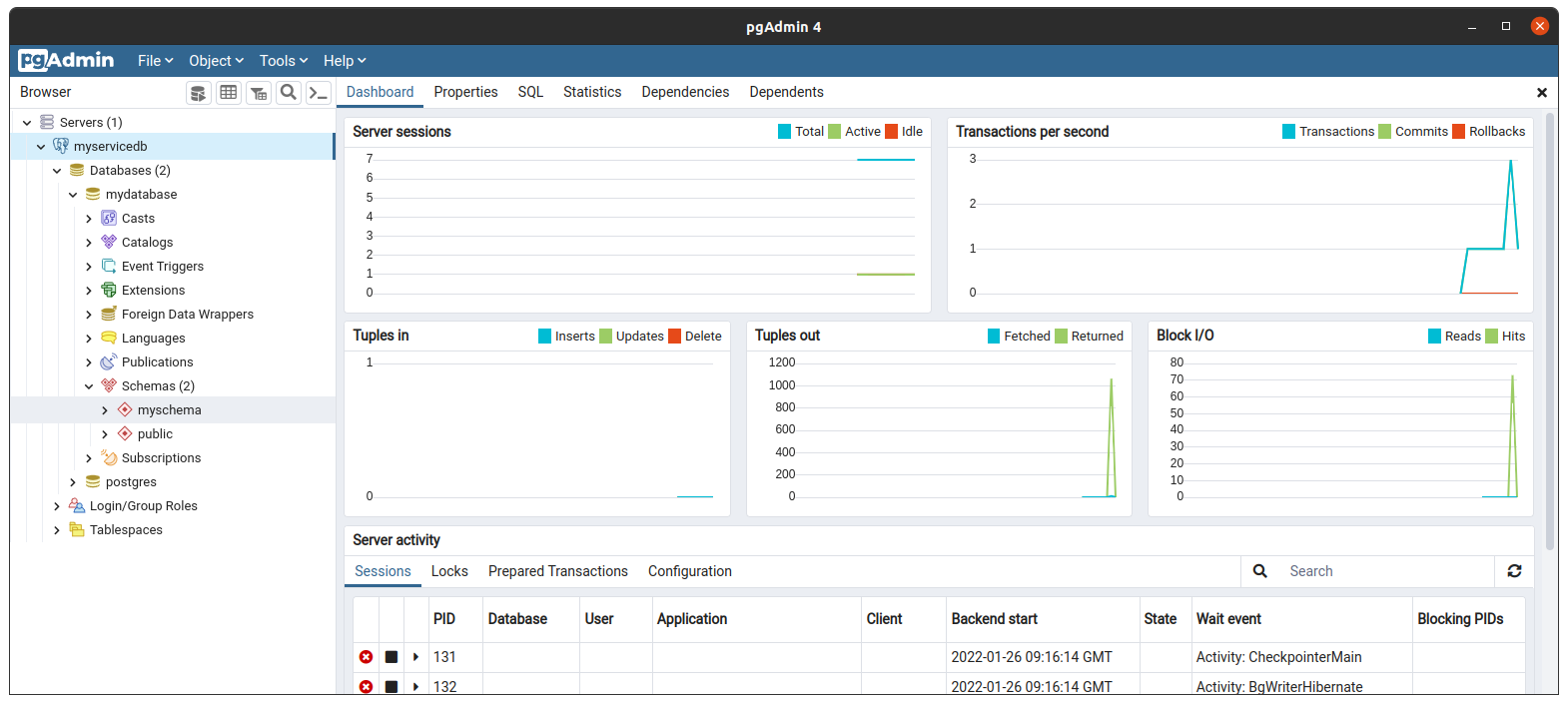
After completing the forms, click on the “Save” button and connect to the server. If you followed the steps correctly you should now get access to the cluster database and see something similar to figure 9.
If you did not create a master password when starting pgAdmin4, you might get a missing crypt key failure.
Figure 9. Control panel for pgAdmin4
If this is your first connection to the database service, it will be almost empty. To store our data we are going to create the following databases, schemas and tables. Use the right button on each of the following fields to create all the items by order:
- Database: Databases >“Create Database”: mydatabase
- Schema: Databases > mydatabase > “Create Schema”: myschema
- Table: Databases > mydatabase > schemas > myschema > “Create Table”: mydata
Now, for the table, we need to specify at least 2 columns to display in our graphs. Click with the right button on “mydata” and select “Create > Column”. Complete the form and repeat with the following information:
- Column 1; Name: time, Data type: time with time zone
- Column 2; Name: value, Data type: real
INSERT INTO myschema.mydata VALUES (TIMESTAMP '2000-01-01 02:00', 1.0); |
Check that you receive “Query returned successfully in <x> msec.” on the “Messages'' panel just below the SQL query. From this point, feel free to add additional data to extend the visualisation to display later.
For simplicity we are using the admin user to connect the database. In a real application you should use pgadmin to create a restricted user for non admin connections.
Once we have the database ready, it is time to connect our Grafana service with the database to display the data. To do so, we navigate to our thematic service main page, login and navigate into “Configuration > Data sources”. Click on “Add data source” and select “PostgreSQL”. The service will request you to complete a settings form with the data we have just used to create the database:
- Name: The name you would like to provide (e.g. mydatabase)
- Host: Postgres service IP in the cluster and port (see figure 6).
- Database: mydatabase.
- User: postgres (For production use a new user with pgadmin).
- Password: The password you selected to deploy your postgresql database.
- TLS/SSL Mode: Disable unless you use TSL inside the cluster.
Now click on the button “Save & test” and go back to the “Data sources” panel. Check that the new created source appears on the list like shown in figure X.
Figure 10. List of available data sources at Grafana configuration

As the last step, go to “Create > Dashboard” from the navigation panel at the left (displayed as a ‘+’ symbol) and click on “Add a new panel”. Now on the query panel, ensure the “Data source” matches the PostgreSQL source we have just created. A SQL form should appear under the panel (if not, click on “+ Query”). Now we have to complete the following fields:
- FROM: [myschema.mydata]; [Time column: time]
- SELECT: [Column: value]
From this point, the panel title should display a plot chart (although probably empty). Select the “Absolute time range” for the 1st of January at 2000, click on “Apply time range”. The graph then will display the data we just introduced by SQL.
Figure 11. Postgresql data visualisation with Grafana
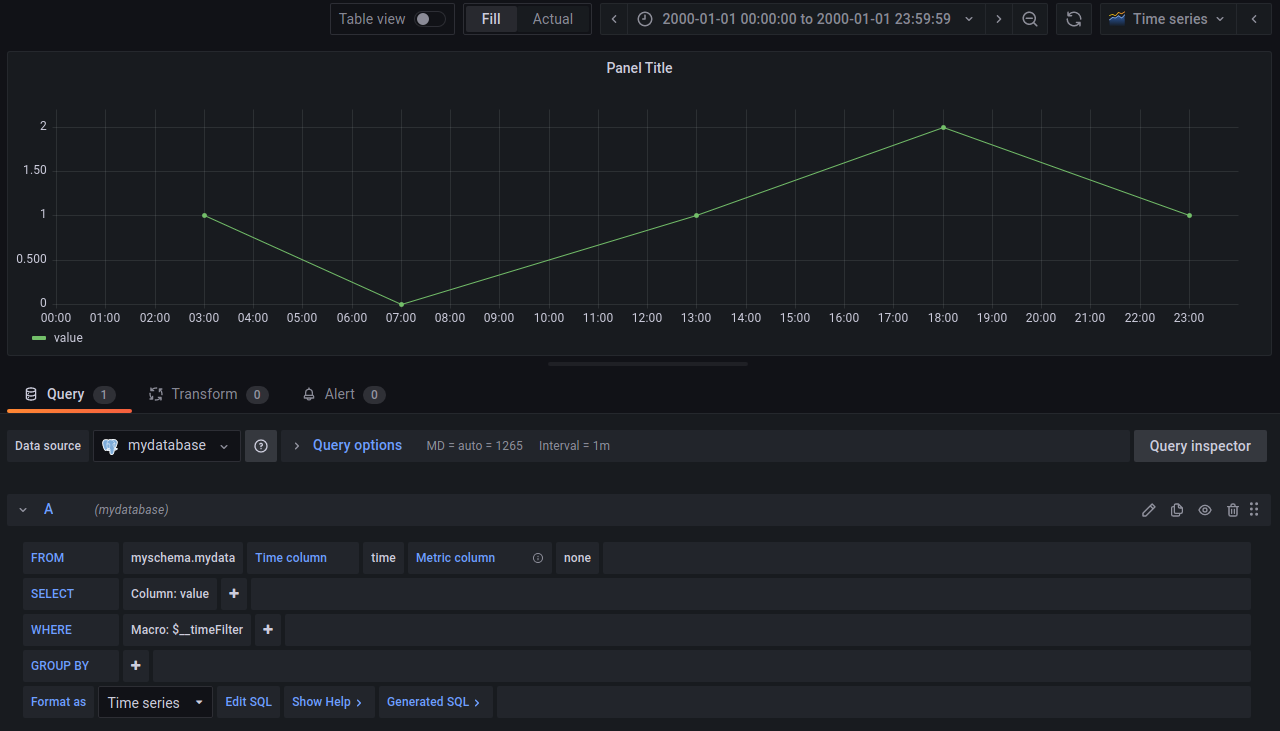
And that is all, click on “Apply” to save and enjoy this nice graph we have just created. Now we leave to you the possibility to experiment with all the features these tools provide. Try for example the following exercises:
- Use a non admin user to collect the data from the graph.
- Introduce new data and check how long it takes to update.
- Add more tables and lines to the plot.
As an advanced homework for experienced kubernetes users, try to extend ingress with an API service to interface your database data. In the case of postgresql, there is a library called PostgREST which you can easily deploy in a few minutes as a service using the docker container. To succeed, you will probably have to make use of the Kubernetes dashboard endpoint to create a deployment, service and ingress resources.
Pay special attention when deploying custom containers which are not official or verified. Deploy only containers that you trust.